Keras/Tensorflowを使った犬と猫の画像分類(CNN転移学習)

学習済みモデルVGG16を利用して、転移学習を実践してみよう
ナノネ、ディープラーニングを実践練習をまたやってみよう!

今回も手書き文字MNISTの画像分類をやるの?

今回は犬と猫の画像だよ。kaggleでデータセットで超有名なやつだよ。
犬猫なら手書き文字より癒されるね~
実行環境は今回もGoogle Colaboratoryを使うね。扱う画像データはファイル形式なので、Google Driveを利用してみたよ。
# ********************************
# Google Colaboratory利用環境 ***
# ********************************
# @2019/05
# Ubuntu 18.04.2 LTS
# Python 3.6.7
# :Keras 2.2.4
# :tensorflow 1.13.1
# :numpy 1.16.3
# :matplotlib 3.0.3
# **************************
# Google Colaboratory準備 ****
# **************************
# Google Driveマウント
from google.colab import drive
drive.mount('/content/drive')
# cd '/content/drive/'My Drive/'Colab Notebooks'
%cd '/content/drive/'My Drive/images
画像用のディレクトリは以下の構成にしているよ。KerasのImageDataGeneratorを使って画像を取得する際、この構成にしておく必要があるんだよ。
画像データのディレクトリ構成¶

訓練用(train)、検証用(validation)、評価用(test)を準備するんだね。
大事なのでは、カテゴリごとサブディレクトリを作って、そこに該当ファイルを入れるんだよ。もし評価用で正解ラベルが無い場合でも、なんらかの名称のサブディレクトリに画像を入れてね(今回はunknownとしたよ)。
オリジナルのデータセットは、Train用25,000、Test用として12,500画像あるんだ。でも全部処理するのは大変なので、今回はTrain画像から一部だけ抜粋して使うことにするね。
# <Colaboratory環境での確認> training data 1500x2
!ls ./data/train/cats | wc -l
!ls ./data/train/dogs | wc -l
# <Colaboratory環境での確認> validation data1 400x2
!ls ./data/validation/cats | wc -l
!ls ./data/validation/dogs | wc -l
# <Colaboratory環境での確認> test data
!ls ./data/test/unknown | wc -l
今回は訓練用(train)3000枚、検証用(validation)1000枚、評価用(test)30枚を準備したんだね。
分類はCNNを使うんだけど、今回はVGG16という学習済みモデルをベースに転移学習を試してみよう。
VGG16っていうのは、なんなの?
VGG16というのは、「ImageNet」と呼ばれる大規模画像データセット(1000クラス)で学習された、16層からなるCNNモデルだよ。画像分類の競技会でも優秀な成績を収め、様々な研究で利用されている有名な学習済みモデルの1つなんだよ。
優秀な画像分類モデルをベースにするなら、心強いね。
しかも、VGG16はKerasから簡単に利用できるんだよ。(モデルの実装に関しては、以下の記事が大変わかりやすかったので、参考にさせていただきましたm(_ _ )m)
さっそくだけど、モデルを構築して犬猫が分類できるように訓練してみよう!(動かすのに苦戦したレベルなので、細かい説明はとてもできないけど、動作した記録として残すね)
ラジャー!
CNNモデル構築(VCC16転移学習)と訓練¶
# ************************
# モデル構築(CNN) *******
# ************************
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization
from keras.models import Model, Sequential
from keras.callbacks import EarlyStopping, ModelCheckpoint, CSVLogger
import numpy as np
# 乱数固定 ----------
import keras.backend as K
import tensorflow as tf
np.random.seed(seed=0)
session_conf = tf.ConfigProto(
intra_op_parallelism_threads=1,
inter_op_parallelism_threads=1)
tf.set_random_seed(0)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
# 画像ファイルパス ----------
train_data_dir = "data/train/" # training dir path
validation_data_dir = "data/validation/" # validation dir path
# モデル条件設定 ----------
img_width, img_height = 150, 150 # モデル画像サイズ
nb_train_samples = 3000 # training data (1500x2)
nb_validation_samples = 1000 # validation data (500x2)
epochs = 50 # エポック数
batch_size = 32 # バッチ数
nb_category = 2 # カテゴリ数(cat, dog)
# 画像データのジェネレータ ----------
# 訓練用
train_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode="categorical")
# 検証用
validation_datagen = ImageDataGenerator(rescale=1. / 255)
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode="categorical")
# モデル定義 ----------
# モデルVGG16(not include Top)
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# モデルTop
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu', kernel_initializer='he_normal'))
top_model.add(BatchNormalization())
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_category, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# layer14までの重みパメータを固定する(訓練で更新しない)
for layer in model.layers[:15]:
layer.trainable = False
# コールバック
# early_stopping_cb = EarlyStopping(
# monitor='val_acc', patience=10, verbose=1, mode='max')
# checkpoint_cb = ModelCheckpoint(
# './{epoch:03d}-{val_acc:.5f}.hdf5', save_best_only=True)
csvlogger_cb = CSVLogger('./history.csv')
# コンパイル ----------
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.rmsprop(lr=5e-7, decay=5e-5),
metrics=['accuracy'])
model.summary()
# *******************
# 訓練実行 *********
# *******************
history = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[csvlogger_cb])
# モデルを保存
model.save("model.h5")
時間(画像ファイルのキャッシュ有無でも違うけど、20~10分位所要)かかったけど、無事に訓練が終ったみたい。犬猫の分類できるようになったかな?
50エポック訓練して、訓練データの正答率(acc)が0.90で、検証データでの正答率(val_acc)は0.88という結果。データ数も絞っているから、まずまずの結果じゃないかな?
訓練履歴を簡単なグラフでプロットしてみよう。
# *******************************
# 訓練履歴をグラフで可視化 *****
# *******************************
import matplotlib.pyplot as plt
import pandas as pd
history = pd.read_csv('history.csv')
history_rows = len(history)
# accuracy
plt.plot(range(1, history_rows + 1), history['acc']) # training
plt.plot(range(1, history_rows + 1), history['val_acc']) # validation
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()
# loss
plt.plot(range(1, history_rows + 1), history['loss'])
plt.plot(range(1, history_rows + 1), history['val_loss'])
plt.title('model accuracy')
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='best')
plt.show()


う~ん。少しギザギザしているけど、どうなんだろ??
上のコード以外にもいろいろ試行錯誤したんだけど、学習がうまく進まない(><)、もっと酷いのも一杯見てきたから...いいほうかも。
モデルが完成したから、訓練に全く利用していないテストデータで評価してみよう。うまく犬猫が分類できるかな?画像は少量だけど30枚準備したよ。
テストデータを使って評価¶
# モデル読み込み(@保存ファイルより再読み込み用)
from keras.models import load_model
model = load_model("./model.h5")
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.layers import Dense, Dropout, Flatten, Input, BatchNormalization
from keras.models import Model, Sequential, load_model
import pandas as pd
import numpy as np
import os
# ****************************
# テストデータで予測実行 *****
# ****************************
test_data_dir = "data/test/" # テスト用データdir
img_width, img_height = 150, 150 # 画像サイズ(訓練同)
nb_test_samples = 30 # 画像データ数
batch_size = 1 # バッチサイズ
nb_category = 2 # カテゴリ数(cat, dog)
# 画像データのジェネレータ(テスト用)
test_datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
# 分類予測
pred = model.predict_generator(
test_generator,
steps=nb_test_samples,
verbose=1)
# ****************************
# テストデータの予測結果 *****
# ****************************
labels = ['cat', 'dog']
# データ0~14 -> Cat画像
# データ15~29 -> Dog画像
print("*** test data [cat] *****")
for i in pred[0:15]:
cls = np.argmax(i)
score = np.max(i)
print("pred: {} score = {:.3f}".format(labels[cls], score))
print("-" * 30)
print("*** test data [dog] *****")
for i in pred[15:30]:
cls = np.argmax(i)
score = np.max(i)
print("pred: {} score = {:.3f}".format(labels[cls], score))
猫画像で1枚誤認したようだけど、結構うまく分類できているかも。
間違えちゃった画像はスコア(識別の自信)も低くなっているよね。自信を持って誤認するときもあるけど...。
ところで、CNNモデルは画像のどの辺の特徴から、犬と猫を識別しているんだろね??モモノキ、モデル中身って見えないものかなぁ...。
ナノネ、可視化するよさげな手法を見つけたので一度試してみよう。Grad Cam(Gradient-weighted Class Activation Mapping)という手法で、画像のどの辺りの特徴が分類に大きく影響しているか、カラーマッピングできるみたいだよ。
Grad Camの実装は、以下の記事を元にさせて頂きました。(やりたかった特徴箇所への色付けができて大変感謝です)
CNNは画像のどこに注目しているの?(Grad Camでカラーマッピング)¶
カラーマッピングする関数を定義して、
import pandas as pd
import numpy as np
import cv2
from keras import backend as K
from keras.preprocessing.image import array_to_img, img_to_array, load_img
from keras.models import load_model
K.set_learning_phase(1) # set learning phase
# *************************************************
# Gradient-weighted Class Activation Mapping *****
#**************************************************
# 呼び出し用関数
def Grad_Cam(input_model, x, layer_name):
# 前処理
X = np.expand_dims(x, axis=0)
X = X.astype('float32')
preprocessed_input = X / 255.0
# 予測クラス算出
predictions = model.predict(preprocessed_input)
class_idx = np.argmax(predictions[0])
class_output = model.output[:, class_idx]
# 勾配取得
conv_output = model.get_layer(layer_name).output
grads = K.gradients(class_output, conv_output)[0]
gradient_function = K.function([model.input], [conv_output, grads])
output, grads_val = gradient_function([preprocessed_input])
output, grads_val = output[0], grads_val[0]
# 重み平均化、cam算出
weights = np.mean(grads_val, axis=(0, 1))
cam = np.dot(output, weights)
# ヒートマップ合成
w = x.shape[0]
h = x.shape[1]
cam = cv2.resize(cam, (w, h), cv2.INTER_LINEAR)
cam = np.maximum(cam, 0)
if cam.max() == 0: # 色付け不可(ブルー画像になる)
return None
cam = cam / cam.max()
jetcam = cv2.applyColorMap(np.uint8(255 * cam), cv2.COLORMAP_JET)
jetcam = cv2.cvtColor(jetcam, cv2.COLOR_BGR2RGB)
jetcam = (np.float32(jetcam) + x / 2)
return jetcam
色付け実行!
import os
import glob
import matplotlib.pyplot as plt
# *****************************************************
# Grad Camで色付けして可視化(テストデータで実行) ******
# *****************************************************
labels = ['cat', 'dog']
test_dir = 'data/test' # テスト画像dir
# (正解ラベルなしを仮定してunknowディレクトに保存した)
test_files = sorted(glob.glob(os.path.join(test_dir, '*', '*.jpg')))
test_data_count = len(test_files)
for idx in range(test_data_count):
file = test_files[idx] # file path (試しで30データ)
file_name = os.path.basename(file)
img_original = load_img(file, target_size=(150,150))
# grad cam
arr = img_to_array(img_original)
layer_name = 'block5_conv3' # 最後の畳み込み層
grad_cam = Grad_Cam(model, arr, layer_name) # grad_cam呼び出し
if grad_cam is None:
layer_name = 'block5_conv2' # 最後のひとつ前の畳み込み層(ラストがダメな場合)
grad_cam = Grad_Cam(model, arr, layer_name)
img_grad_cam = array_to_img(grad_cam)
# 画像表示
fig = plt.figure(figsize=(12, 4))
# Image Original
fig.add_subplot(1, 3, 1)
plt.imshow(img_original)
plt.title(file_name)
plt.axis('off')
# Image Grad-Cam
fig.add_subplot(1, 3, 2)
plt.imshow(img_grad_cam)
plt.title(layer_name)
plt.axis('off')
# Pie Graph prediction score
data_pred = pred[idx]
colors = ["orange", "green"] # pred dog
fig.add_subplot(1, 3, 3)
plt.pie(data_pred,
labels=labels,
colors=colors,
counterclock=False,
startangle=90,
labeldistance=0.2,
autopct="%.1f%%",
pctdistance=0.7,
textprops={'color': 'white', 'horizontalalignment':'center'})
plt.show()
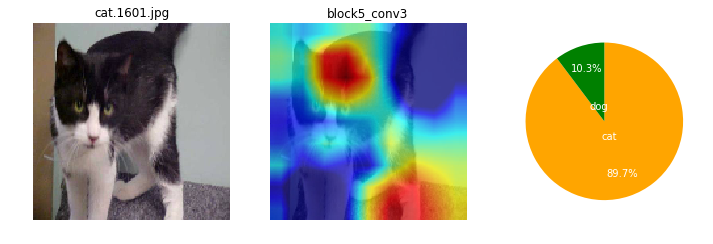
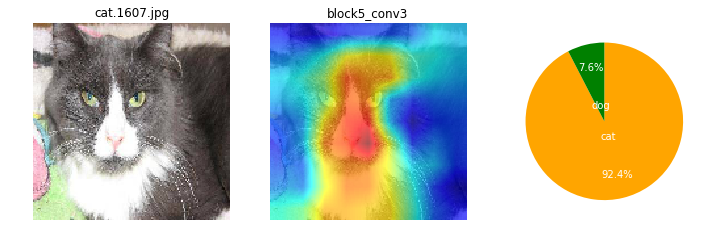


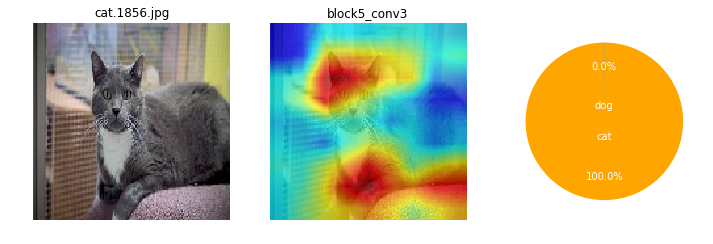
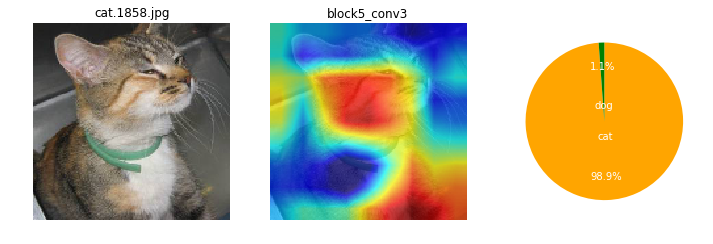


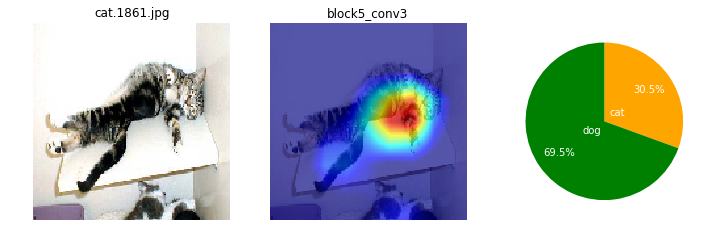


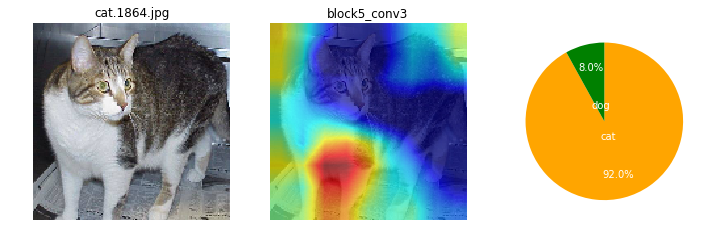


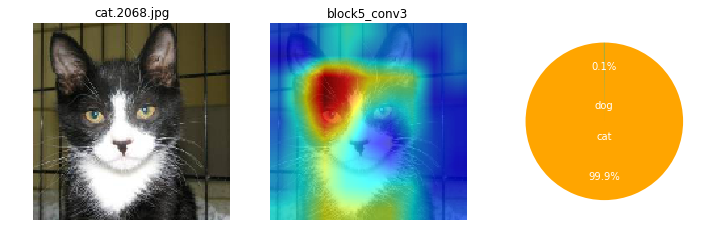




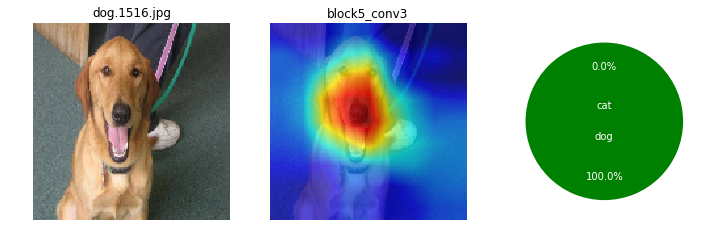
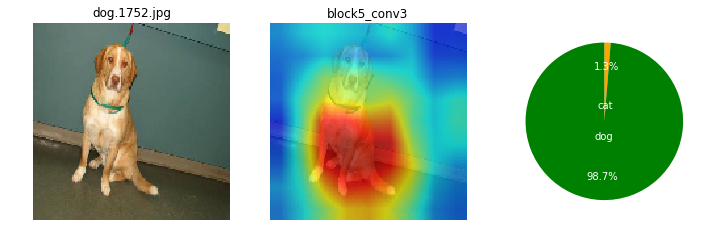
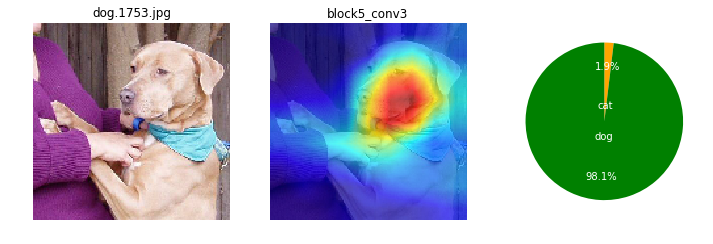

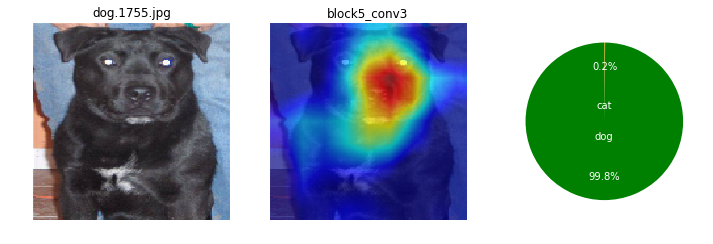
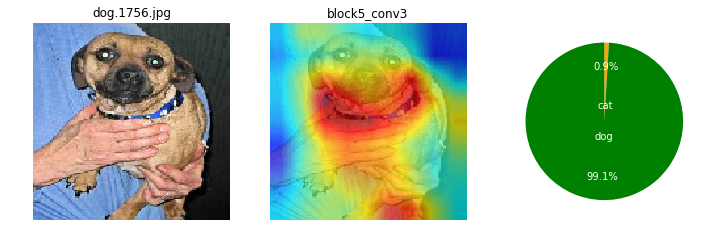

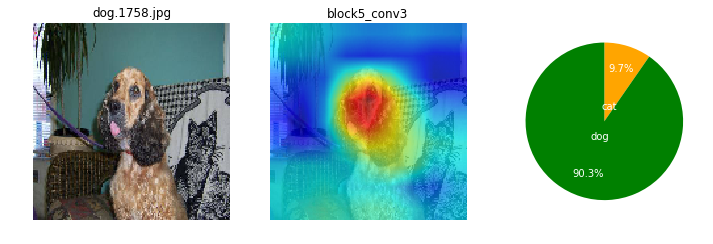

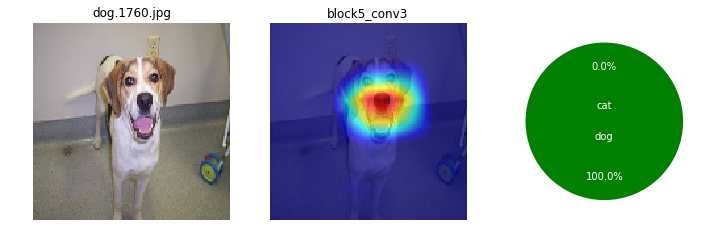

画像によっても、特徴として捕えている箇所がまちまちだけど。ここを見て識別してるのかと、なんとなくイメージね。
ワンちゃんは、顔の鼻回りと胴体がくっくりしているかも。首輪を1つあるね。
ネコちゃんは、全体的にもや~ん?とした感じかも。
でも、なんとか犬猫の分類ができたみたいで、よかったよ。
続いて、今回の実装説明~っと行きたいところだけど...説明を書くにはまだまだ未熟なので、今回は動かしたよ~でおしまいね。
やっぱり、そうなね~、苦戦してたもんね。
犬猫以外の画像で試したり、カテゴリ数を増やしたりしても練習になりそうだね。
あとで、自力で収集した画像でも分類してみようかなぁ。画像を集めるのが大変そうだけど。
またね!
お疲れ様でした。またね!




0 件のコメント :
コメントを投稿